- Published on
Building Self-Healing AI Medical Coding Systems with MCP Code Execution
- Authors

- Name
- Varun
- @varunzxzx
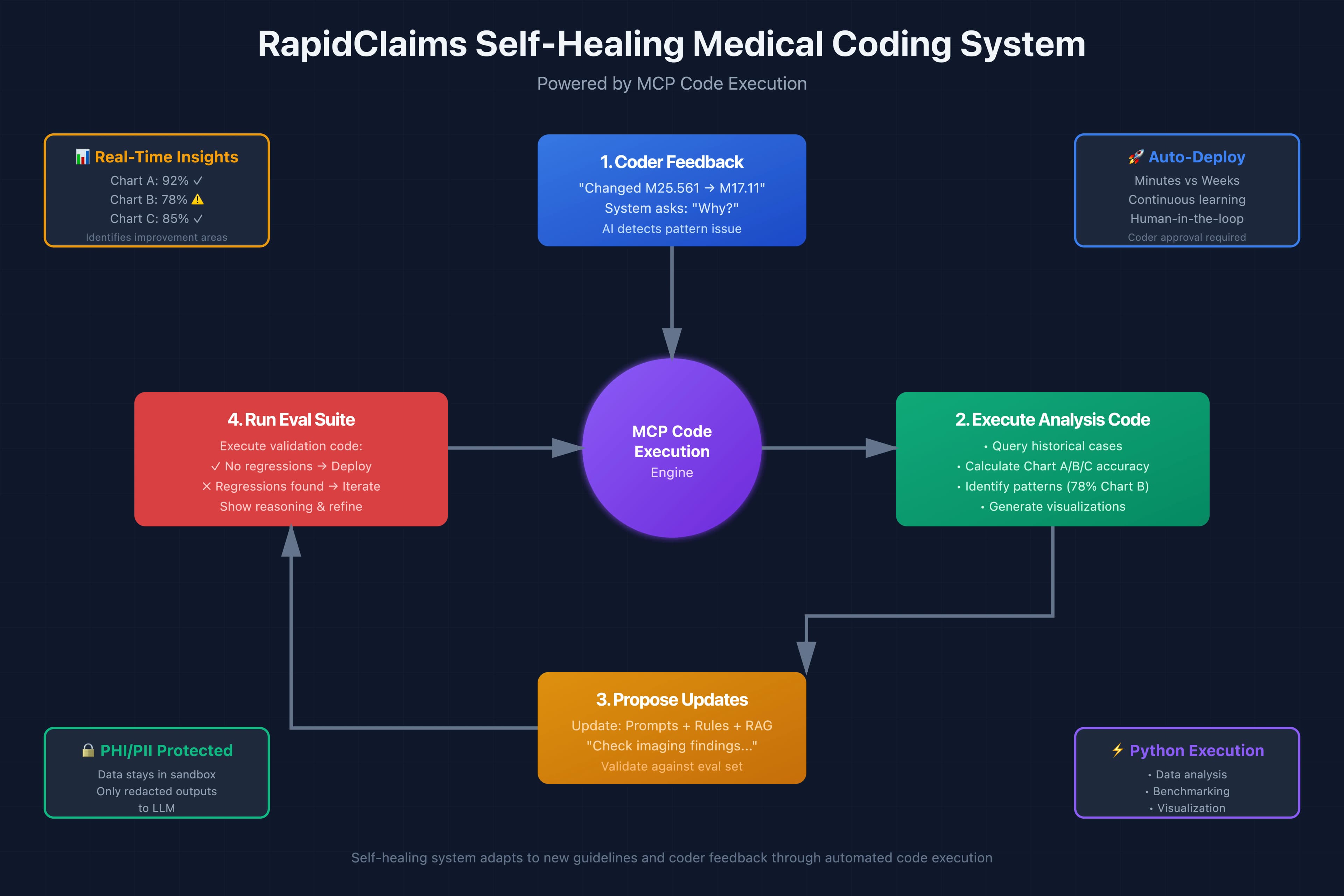
The healthcare AI landscape is evolving rapidly, and nowhere is this more evident than in medical coding, where regulatory updates, payer-specific rules, and clinical documentation guidelines change constantly. At RapidClaims, we've built a self-healing system that stays current with these changes, and the key enabler is code execution through the Model Context Protocol (MCP).
In this post, we'll explore how we leverage MCP's code execution capabilities to create an adaptive medical coding agent that learns from coder feedback, validates changes against historical data, and updates itself, all while maintaining strict PHI/PII compliance.
The Challenge: Keeping AI Medical Coding Current
Medical coding isn't static. ICD-10, CPT, and HCPCS codes evolve. CMS releases quarterly updates. Individual hospitals have their own coding conventions. An AI system that was accurate last month might systematically miss nuances this month. Traditional approaches to updating AI models face several problems:
- Slow feedback loops: Collecting feedback, retraining models, and deploying updates can take weeks
- Lack of transparency: When the AI changes behavior, understanding why is difficult
- Binary updates: You either deploy the change or you don't, there's no iterative refinement
- Validation bottlenecks: Testing against comprehensive eval sets requires engineering resources
We needed a system that could iterate faster, explain its reasoning, and validate changes automatically. Code execution with MCP became our solution.
What is MCP Code Execution?
The Model Context Protocol (MCP) is an open standard that enables AI models to securely connect to external tools and data sources. As highlighted in Anthropic's engineering blog, code execution through MCP allows AI models to:
- Write and execute code in sandboxed environments
- Perform complex data analysis and transformations
- Generate visualizations and reports
- Validate hypotheses with real computations
Rather than just talking about code, the AI can actually run it and see results, enabling a new class of applications where the model becomes an active problem-solver rather than just a text generator.
Our Self-Healing Architecture
Here's how RapidClaims' auto-healing medical coding system works:
1. Feedback Collection
When a medical coder reviews AI-suggested codes, they might change, add, or delete codes. Our system captures these corrections and critically asks the coder to explain their reasoning through a conversational agent.
Example dialogue:
System: "I noticed you changed code M25.561 (Pain in right knee) to M17.11
(Unilateral primary osteoarthritis, right knee). Can you help me understand
when osteoarthritis should be coded instead of general knee pain?"
Coder: "The documentation mentioned joint space narrowing and bone spurs on
the X-ray report. Those are diagnostic indicators of OA, not just pain."
2. Code Execution for Analysis
This is where MCP code execution becomes powerful. The agent doesn't just record this feedback, it immediately writes and executes Python code to:
- Analyze historical patterns: Query our database of past coding cases to find similar scenarios
- Identify systemic issues: Calculate accuracy metrics across different encounter types
- Generate hypotheses: Determine if this is an isolated case or a broader pattern
Here's a simplified example of what the agent might execute:
import pandas as pd
import numpy as np
from collections import Counter
# Load historical ENM (Evaluation and Management) coding data
df = pd.read_csv('enm_historical_cases.csv')
# Filter cases with knee pain documentation
knee_cases = df[df['clinical_notes'].str.contains('knee pain', case=False)]
# Analyze AI predictions vs actual codes
prediction_analysis = knee_cases.groupby(['ai_predicted_code', 'actual_code']).size()
# Calculate accuracy by chart level (A, B, C complexity)
chart_accuracy = {}
for level in ['A', 'B', 'C']:
level_cases = knee_cases[knee_cases['chart_level'] == level]
accuracy = (level_cases['ai_predicted_code'] == level_cases['actual_code']).mean()
chart_accuracy[level] = accuracy
# Identify lowest hanging fruit
sorted_accuracy = sorted(chart_accuracy.items(), key=lambda x: x[1])
lowest_accuracy_level = sorted_accuracy[0][0]
# Find common patterns in misclassifications
misclassified = knee_cases[knee_cases['ai_predicted_code'] != knee_cases['actual_code']]
common_patterns = Counter(misclassified['diagnosis_description'].str.lower())
print(f"Chart Level Accuracy: {chart_accuracy}")
print(f"Lowest accuracy level: {lowest_accuracy_level} ({sorted_accuracy[0][1]:.2%})")
print(f"Most common misclassification patterns: {common_patterns.most_common(5)}")
The agent can execute this code and immediately see that Chart Level B cases have the lowest accuracy (perhaps 78% vs 92% for Level A and 85% for Level C), and that knee pain cases with imaging findings are frequently misclassified.
3. Proposed Changes and Validation
Based on the analysis, the agent proposes specific changes:
- Prompt updates: Add guidance about checking imaging reports for diagnostic indicators
- Rule-based logic: Create a rule that escalates from pain codes to diagnostic codes when imaging findings are present
- RAG knowledge: Add this coder's explanation as a reference example
But here's the crucial part: before deploying these changes, the system validates them against a comprehensive eval set of historical cases with known correct codes.
4. Iterative Refinement with Real-Time Feedback
The agent executes validation code:
# Apply proposed changes to eval set
eval_results = run_coding_pipeline(
eval_cases,
prompt_version='v2_with_imaging_guidance',
rules={'check_imaging_for_diagnosis': True},
rag_examples=['case_12847_knee_oa']
)
# Compare accuracy
baseline_accuracy = 0.78 # Previous Chart B accuracy
new_accuracy = (eval_results['predicted_code'] == eval_results['actual_code']).mean()
# Identify any regressions
regressions = eval_results[
(eval_results['baseline_correct'] == True) &
(eval_results['new_prediction_correct'] == False)
]
if len(regressions) > 0:
print(f"⚠️ Found {len(regressions)} regression cases")
print("Examples:", regressions[['case_id', 'diagnosis', 'issue']].head())
else:
print(f"✅ No regressions. Accuracy improved from {baseline_accuracy:.2%} to {new_accuracy:.2%}")
If the eval breaks meaning the changes caused regressions in previously correct cases, the agent shows the coder exactly what went wrong and asks for additional guidance. This continues iteratively until all evals pass.
5. The Power of Custom Workflows
What makes this approach transformative is that the agent can build custom analytical workflows on the fly. Depending on the complexity of the feedback, it might:
- Generate data visualizations showing accuracy trends over time
- Run benchmark comparisons against coding accuracy metrics
- Perform A/B testing simulations across different prompt variations
- Optimize retrieval strategies in the RAG system
For complex scenarios like incorporating a major CMS guideline update affecting multiple code families, the agent can orchestrate multi-step workflows that would traditionally require data scientists and ML engineers.
Security and Privacy: PHI/PII Protection
Medical coding inherently involves sensitive patient health information. This is where the architecture of code execution with MCP provides a critical advantage: all PHI/PII stays within the sandboxed execution environment.
Here's how we maintain compliance:
Data Stays in the Sandbox
When the agent executes code, it works with the full historical dataset including clinical notes, diagnoses, and demographic information. However, the LLM itself never sees this raw data. Instead, it only receives:
- Aggregated statistics (e.g., "Chart B accuracy: 78%")
- Anonymized patterns (e.g., "Most common issue: diagnostic indicators in imaging")
- Redacted examples with identifiers removed
Example of Redacted Output
# Code executed in sandbox (has access to PHI)
case = get_case_by_id('12847')
# case contains: patient_name, DOB, SSN, clinical_notes, etc.
# Analysis
analysis = analyze_coding_decision(case)
# Only aggregated, redacted output is returned to LLM
return {
'case_type': 'knee_pain_with_imaging',
'chart_level': 'B',
'ai_prediction': 'M25.561',
'correct_code': 'M17.11',
'key_documentation': '[REDACTED] mentioned joint space narrowing and bone spurs',
'reasoning': 'Imaging findings indicate OA rather than general pain'
}
The LLM sees the reasoning and patterns but never the actual patient data. This separation is built into the MCP architecture, the code execution server handles sensitive data, and only safe outputs cross the boundary.
Audit Trail
Every code execution is logged with:
- What code was run
- What data was accessed
- What outputs were generated
- Who initiated the interaction
This provides full auditability for HIPAA compliance while enabling powerful AI capabilities.
Real-World Impact
The impact of this self-healing system has been substantial:
Faster Adaptation
Previously, incorporating coder feedback into our AI models could take weeks from collecting feedback, to analyzing patterns, to updating prompts or retraining, to validation, to deployment. Now, the feedback loop happens in minutes to hours. A coder can explain a coding nuance in the morning, and by afternoon, the agent has validated and deployed the improvement.
Complex Workflow Automation
The most significant benefit is that the agent can now handle complex scenarios that previously required ML engineers. For instance, when CMS released new E/M coding guidelines, our agent:
- Executed code to identify all affected historical cases
- Analyzed the specific documentation patterns that triggered changes
- Proposed updates to prompts, rules, and RAG examples
- Validated across 10,000+ eval cases
- Generated a detailed report of changes and their impact
This would have been a multi-week project for our engineering team. The agent completed it in a few hours with coder oversight.
Transparency and Trust
Medical coders can see exactly why the AI makes decisions and how their feedback influences the system. The agent can generate visualizations like:
- Accuracy trends before and after updates
- Distribution of errors by code category
- Comparison of AI performance across different hospitals or specialties
This transparency builds trust and makes coders active participants in improving the AI.
Building Your Own MCP Code Execution Server
We built a custom MCP server for our code execution needs. While Anthropic provides reference implementations, building a custom server gives you fine-grained control over:
- Execution environment: We use a hardened Python environment with only approved libraries
- Resource limits: CPU, memory, and execution time constraints
- Data access controls: The server enforces what data can be accessed and how
- Output sanitization: Automatic redaction of PHI/PII before results return to the LLM
Here's a simplified example of our MCP server structure:
from mcp import MCPServer, Tool
import docker
import ast
class MedicalCodingMCPServer(MCPServer):
def __init__(self):
super().__init__()
self.register_tool(
Tool(
name="execute_python",
description="Execute Python code for medical coding analysis",
input_schema={
"type": "object",
"properties": {
"code": {"type": "string"},
"context": {"type": "string"}
}
},
handler=self.execute_python_handler
)
)
async def execute_python_handler(self, code: str, context: str):
# Validate code for security
self._validate_code(code)
# Execute in isolated Docker container
container = docker.from_env().containers.run(
image="medical-coding-python:latest",
command=f"python -c '{code}'",
volumes={'/data/medical_coding': {'bind': '/data', 'mode': 'ro'}},
mem_limit="2g",
cpu_quota=50000,
network_disabled=True,
detach=True
)
# Get output
result = container.wait()
output = container.logs().decode('utf-8')
# Redact PHI/PII
sanitized_output = self._redact_phi(output)
return {
"status": "success" if result['StatusCode'] == 0 else "error",
"output": sanitized_output
}
def _validate_code(self, code: str):
"""Ensure code doesn't contain dangerous operations"""
# Parse AST and check for forbidden operations
tree = ast.parse(code)
# ... validation logic ...
def _redact_phi(self, text: str):
"""Remove or mask PHI/PII from output"""
# ... redaction logic using regex and NER models ...
return text
Lessons Learned
Building this system taught us several key lessons:
1. Start with Read-Only Access
Initially, we only allowed the agent to read and analyze data. Only after extensive testing did we enable it to propose and validate changes to prompts and rules. This incremental approach built confidence.
2. Clear Boundaries are Essential
The agent is powerful but not autonomous. Medical coders must approve all changes before deployment. The system is a tool that amplifies coder expertise, not a replacement for it.
3. Observability is Critical
We log everything every code execution, every analysis, every proposed change. When something goes wrong (and it occasionally does), we need to understand exactly what the agent was thinking.
4. Eval Sets are Your North Star
Having a comprehensive, continuously updated eval set of historical cases with verified correct codes is essential. This is what gives us confidence that changes improve the system rather than breaking it.
5. The Right Abstractions Matter
We provide the agent with high-level tools like analyze_coding_accuracy() and run_benchmark() rather than raw database access. This makes the agent more effective and maintains security boundaries.
The Future of AI Medical Coding
Code execution with MCP represents a shift from static AI models to adaptive, self-improving systems. In medical coding, where accuracy is critical and the landscape constantly changes, this adaptability is not just convenient, it's necessary.
As Cloudflare highlighted in their Code Mode blog post, code execution turns AI from a text generator into a true reasoning engine that can solve complex problems. In our domain, this means:
- Continuous learning from every coder interaction
- Immediate adaptation to new guidelines
- Transparent decision-making that coders can trust and validate
- Automated workflows for tasks that previously required engineering resources
Most importantly, it keeps the human (the medical coder) at the center. The AI becomes a collaborator that learns from expertise rather than a black box that makes unexplainable decisions.
Getting Started
If you're building AI systems in healthcare or other regulated industries, consider how code execution with MCP might fit your needs:
- Identify repetitive analysis tasks that currently require engineering resources
- Build comprehensive eval sets that can validate changes automatically
- Design clear security boundaries for what code can access and what outputs are safe
- Start with read-only analysis before enabling system modifications
- Keep humans in the loop for all critical decisions
The future of AI in healthcare isn't about replacing expertise, it's about augmenting it with systems that learn, adapt, and improve continuously while maintaining the safety and privacy standards our field demands.
Interested in learning more about building secure, adaptive AI systems for healthcare? Check out Anthropic's MCP documentation and the code execution guide for technical details on getting started.